diedatenlaube.github.io
Blog of #DieDatenlaube
Die Datenlaube der Gartenlaube
Mit Wikidata ‚Die Gartenlaube‘ in Wikisource strukturiert erschließen – ein Werkstattbericht
Christian Erlinger (Q67173261)
Jens Bemme (Q56880673)
Eines der umfangreichsten Projekte der deutschsprachigen Wikisource-Community ist die Bearbeitung und Tiefenerschließung der ersten großen deutschsprachigen Illustrierten „Die Gartenlaube‟.
Seit Beginn des Jahres 2019 werden die transkribierten Artikel dieser Zeitschrift vollständig mit Hilfe von Wikidata formal und inhaltlich erschlossen.1 Wikidata wird dadurch zur offenen und strukturierten Bibliographie der freien Quellensammlung Wikisource. Die Methoden dieser teilautomatisierten bibliographischen Datenextraktion und Erschließung mit verschiedenen Tools in Wikidata wie QuickStatements oder Jupyter Notebooks sind im Folgenden dokumentiert.
Von geschätzt 18.500 Artikel, die ab 1853 bis zum Jahr 1900 in der Gartenlaube erschienen sind, sind per 1. November 2019 bereits 12.990 Artikel in Wikisource vorhanden – basierend auf 40.366 gescannten Seiten: gescannt, transkribiert oder auf Basis der Volltexterkennung (OCR) korrigiert.2
Die Artikel in Wikisource werden allesamt mit einer für Mediawikiprojekte typischen Infobox mit grundlegenen Metadaten ausgestattet. (vgl. Abb. 1) Dies umfasst in der Regel den Titel des Artikels, die Quellenstelle mit Heftnummer, Seitenzahl(en) und das Publikationsjahr. Gegebenenfalls ist auch ein Kurzzusammenfassung und ein Link zu einer relevanten Wikipedia-Seite angegeben, die ggf. das Hauptthema des Textes beschreibt und somit ein erstes Schlagwort darstellt. Darüber hinaus beinhaltet die Infobox noch Links zu den Seitenscans sowie Informationen zum Bearbeitungsstand der Texterschließung nach den Vorgaben der Wikisource-Community. All diese in gewisser Weise „strukturierten‟ (aber nur bedingt maschinenlesbaren) Daten der Wikisource-Seite lassen sich dann in einem Wikidata-Item (vgl. Abb. 2) strukturiert verankern und vor allem für Menschen wie Maschinen gleichermaßen les- und durchsuchbar halten.

Abbildung 1: Infobox des Gartenlaubeartikels "Der Volkspalast im Ostend von London."
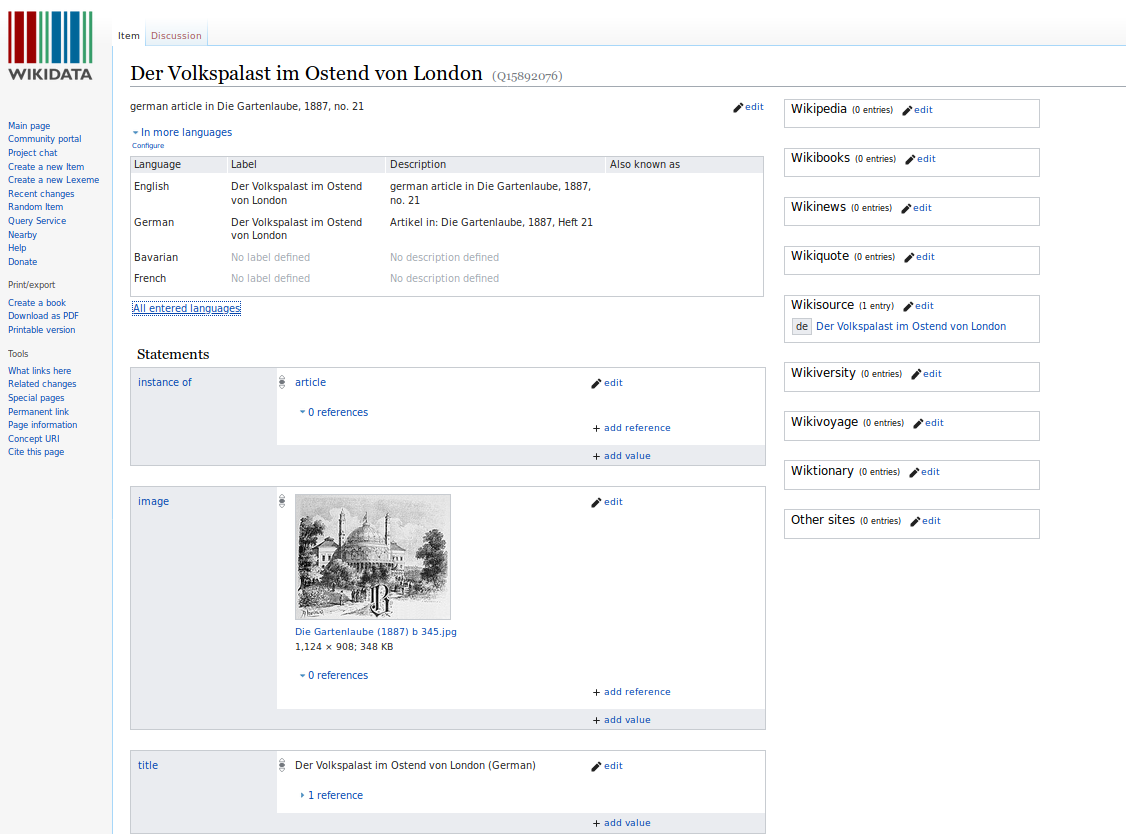
Abbildung 2: Das Frontend des „ältesten‟ Wikidata-Items eines Gartenlaube-Artikels: „Der Volkspalast im Ostend von London‟ (Q15892076 [14.11.2014]) zeigt mehrsprachige Labels, Artikel-Statement, Bild-Verlinkung und Titel
Datenmodell
Wie in allen Portalen des Wiki*versums ist auch in Wikisource die Möglichkeit gegeben, die jeweiligen Wikisource-Pages mit einem spezifischen Datenobjekt (Item) in Wikidata zu verlinken. Im Fall der Gartenlaube bedeutet dies, dass für jeden Artikel ein Wikidata-Item als bibliographischer Datensatz angelegt wird. Ein solches Item sollte ein entsprechendes Mindestset an bibliographischen Informationen des Artikels bereithalten. Das genutzte Basis-Metadatenschma ist in der nachfolgenden Tabelle dargestellt.
| Property/Wikidata-Metadatenfeld | Format/Beschreibung des Inhalts | Beispiel Q61996511 |
|---|---|---|
| label_de | Titel des Artikels (Deutsch) | Jean Paul Richter |
| label_en | Titel des Artikels (English) | Jean Paul Richter |
| description_de | Arikel in: Zeitschrift, Jahrgang, Nr. | Artikel in: Die Gartenlaube, 1853, Heft 34 |
| description_en | german article in Journal, Volume, Issue | german article in Die Gartenlaube, 1853, no. 34 |
| P31 instance of | article Q191067 | |
| P1476 title | Titel des Artikels | Jean Paul Richter |
| P407 language of work or name | German Q188 | |
| P577 publication date | YYYY | 1853 |
| P304 pages | 197 | |
| P433 issue | 18 | |
| P1433 published in | Journal | Die Gartenlaube Q655617 |
| P921 main subject | Jean Paul Q77079 | |
| dewikisource_sitelink | Titel des Artikels | Jean Paul Richter |
Tabelle 1: Basis-Metadatenmodell für Gartenlaube-Artikel in Wikidata3
Die Flexibilität und Offenheit des Datenmodells in Wikidata insgesamt erlaubt es für die spezifischen Items weitere Statements zu ergänzen, wie beispielhaft in der Tabelle 2 angeführt. Dies wäre bspw. die Ergänzung und Verlinkung von Illustrationen, der Nennung eines Illustrators, sofern auffindbar Links in Bibliothekskataloge zu den entsprechenden lokalen bibliographischen Fundstellen oder schlicht was sonst noch denkbar und möglich erscheint oder dereinst – durch Erzeugung neuer Wikidata-Properties für formale und inhaltliche Erschließung – möglich sein wird.
| Property/Wikidata-Metadatenfeld | Format/Beschreibung des Inhalts | Beispiel Q61996511 |
|---|---|---|
| label_[Multiple_Languages] | Titel des Artikels in weiteren Sprachen – Tendenziell im Original, gegebenenfalls transliteriert. | Jean Paul Richter |
| description_[Multiple_Languages] | Beschreibung des Items in weiteren Sprachen | Artikel in: Die Gartenlaube, 1853, Heft 34 |
| P136 genre | Literaturgattung | poem Q5185279 |
| P18 image | Illustrationen – direkte Verlinkung mit Bild auf Commons | |
| P110 illustrator | Illustrator eines Werks | German Q188 |
| P1343 described by source | Externe Fundstelle | Regional bibliography of Saxony Q61729277 |
| P996 scanned file on Wikimedia Commons | Verlinkung der Quelltext-Scans auf Commons | |
| [wikiproject]_sitelink | Sitelinks zu weiteren Wiki*Projekten (z.B. Wikipedia-Link zum Werk) |
Tabelle 2: Beispiele weiterer [optionaler] Eigenschaften eines bibliographischen Items der Gartenlaube
Die Verknüpfung und Erschließung von Wikisource mittels Wikidata in Projekten mit historischen Texten (unabhängig davon, ob es sich um selbständige oder unselbständige Literatur handelt) ist ein erster Schritt. Darauf aufbauend kann weiteres Augenmerk auf ein drittes Wikimediaportal gelegt werden, ohne das die Volltexterschließung auf Wikisource so nicht möglich wäre: Wikimedia Commons. Auf Commons sind sämtliche für Wikisourceprojekte notwendigen Quelldaten gespeichert, die rohen Scans der Einzelseiten sowie extrahierte und bearbeitete Illustrationen. Insbesondere durch die Etablierung von Structured Data On Commons – der Einbindung von Linked Data nach dem Vorbild und unter Einbeziehung von Wikidata – ergeben sich hier seit dem Frühjahr 2019 neue und vor allem langfristig sehr nützlich erscheinende Beziehung.4 In Wikidata erzeugte bibliographische Items können nun in den Commons als stabiler Link bzw. Fundstelle für die jeweils in den Zeitungsartikeln vorhandenen Illustrationen oder Seitenscans verwendet werden. Das Nachweissystem für die Scans als Quelldokumente der folgenden Artikeltranskriptionen würde damit noch stabiler.
Anzahl und Qualität der Artikel-Items in Wikidata beim Projektstart 2019
Per 1. März 2019 hatten 7.599 Artikel der Gartenlaube ein verlinktes Item in Wikidata. Eine SPARQL-Abfrage nach Artikeln mit dem Statement „published in‟ „Die Gartenlaube‟ ist aber mit den Daten des damaligen Zeitpunktes nicht möglich, da den vorhandenen Items als Veröffentlichungsort nicht die Zeitschrift selbst, sondern ein Jahrgangs-Item (z.B. „Gartenlaube 1878‟) als Fundstelle eingetragen wurde. Der Wert an bereits vorhandenen Wikidata-Items der Gartenlaube errechnet sich aus der gegenwärtig verfügbaren Liste aller Wikidata-Items unter nummerischer Auswertung der Q-ID der Wikidata-Items,5 um auf ein enstprechend frühes Anlagedatum des Items zu schließen (Konkret handelt es sich dabei um alle Gartenlaube-Items mit einer ID kleiner Q50000000).6
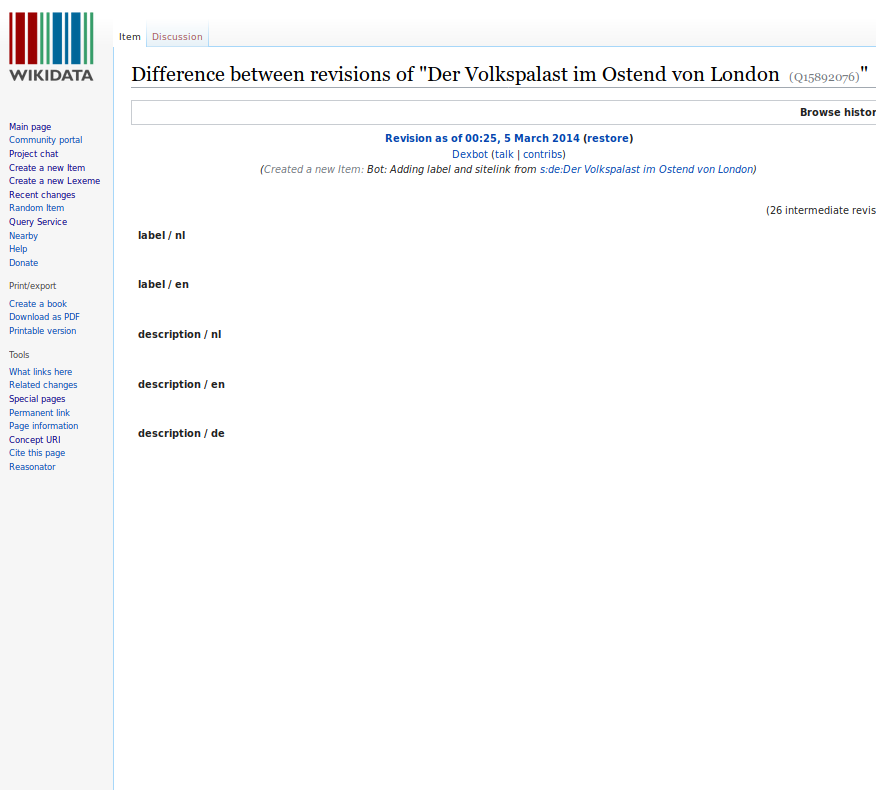
Abbildung 3: Status des „ältesten‟ Wikidata-Items des Gartenlaube-Artikels „Der Volkspalast im Ostend von London‟ (Q15892076) nach seiner Anlage am 05.03.2014
Der Großteil dieser mehr als 7.000 Items war hinsichtlich der bibliographischen Beschreibung eher dürftig, da es sich dabei um eine semi-automatische Anlage mittels des Tools PetScan oder automatisiert per Bot handelte, bei der auf Basis der jeweiligen Jahrgangskategorie in Wikisource Wikidata-Items nur rudimentär angelegt wurden (wie für das älteste Gartenlaube-Item in Abbildung 3 gezeigt).
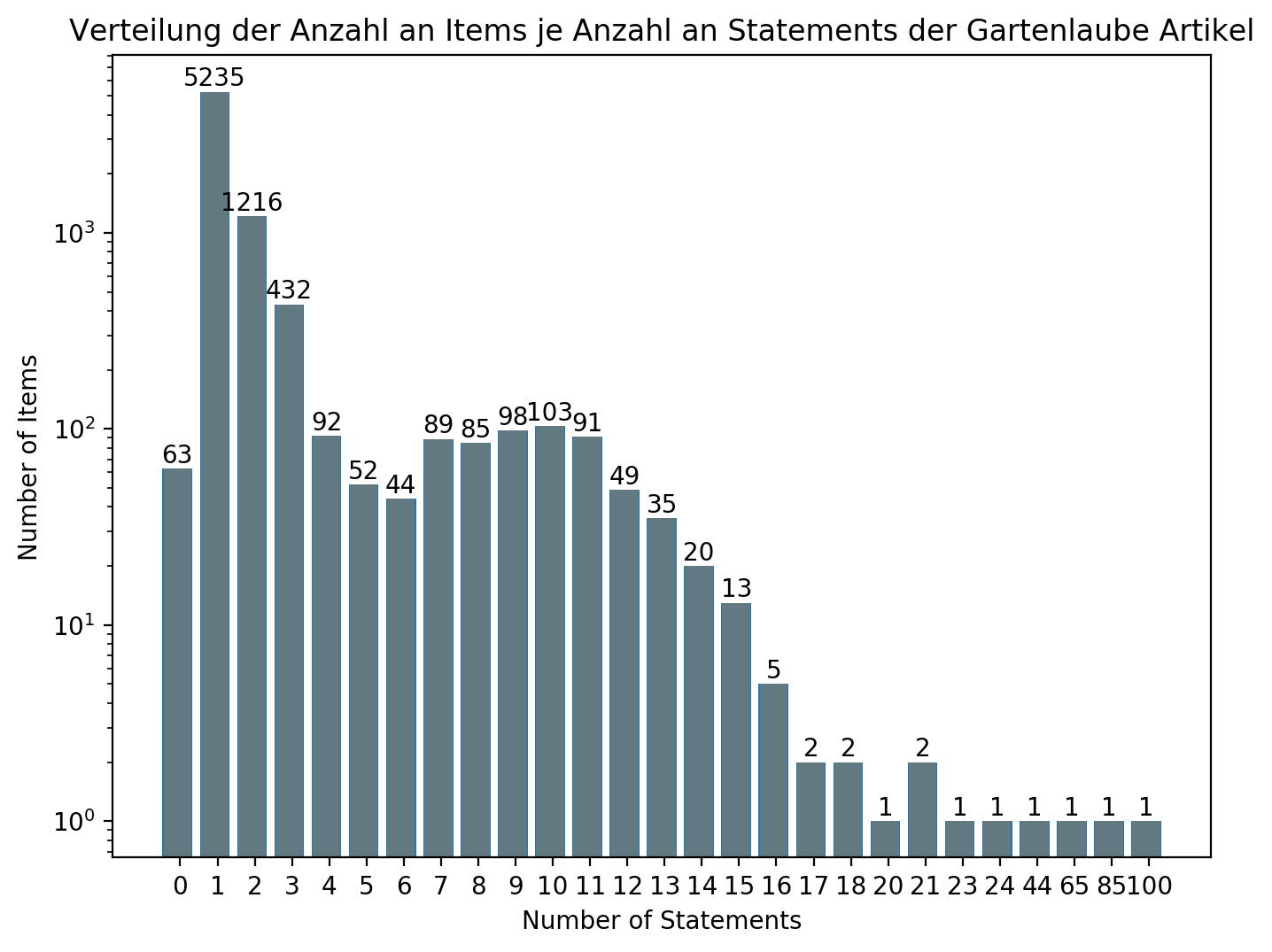
Abbildung 4: Verteilung der Anzahl an Items je Anzahl an Statements der Gartenlaube Artikel
Die zum Zeitpunkt 9. März 2019 vorhandenen Items hatten im Schnitt zwei Statements.7 Die beiden am häufigst eingesetzten Properties waren dabei P31 („instance of‟) und P1433 („published in‟) wie der Tabelle 3 zu entnehmen. Wie aus Abbildung 4 ersichtlich hatten 6.516 Items weniger oder gleich zwei Statements. Bei Items mit einer sehr hohen Anzahl an Statements wie all jenen mit mehr als 20 Statements lohnte sich der genaue Blick auf das Item, da es sich hierbei dann durchwegs um falsche Zuordnungen des Wikisource-Sitelinks des Gartenlaubeartikels zu einem Wikidata-Item handelte. Beispielsweise wurden biographische Artikel direkt dem biographischen Item, d.h. der Person in Wikidata zugeordnet. Eine in einem Artikel beschriebene Person kann respektive soll aber immer nur als verlinktes Schlagwort („main subject‟) im Artikel-Item verwendet werden.
Auf Basis dieser rudimentären Analyse der vorhandenen Einträge war klar, dass nicht nur die fehlenden Items dem neuen Datenmodell gemäß anzulegen sind, sondern auch die große Zahl der bestehenden Items einer gründlichen Überarbeitung bzw. Ergänzung bedurften.8
| Rang | Property | Anzahl der Verwendung |
|---|---|---|
| 1 | P31 | 7671 |
| 2 | P1433 | 1151 |
| 3 | P407 | 940 |
| 4 | P1476 | 636 |
| 5 | P577 | 536 |
| 6 | P6216 | 504 |
| 7 | P921 | 493 |
| 8 | P50 | 383 |
| 9 | P18 | 301 |
| 10 | P361 | 137 |
| 11 | P179 | 99 |
Tabelle 3: Die elf häufigsten Properties mit der Anzahl ihrer Verwendung
Extraktion der vorhandenen Metadaten in Wikisource
Die für die Anlage bzw. das Update der bibliographischen Wikidata-Items notwendigen Informationen finden sich weitestgehend in der Infobox wie in Abbildung 1 gezeigt. In ihrer Gesamtheit abfragbar sind alle Artikel der Gartenlaube in Wikisource anhand der vergebenen Kategorien. Jeder Artikel ist einer Jahrgangskategorie (Kategorie:Die Gartenlaube (YYYY) Artikel) zugeschrieben und diese wiederum ist eine Unterkategorie der Kategorie:Die_Gartenlaube_Artikel.
Zur Extraktion sämtlicher Artikelmetadaten der Gartenlaube wurde ein Python Skript in einem Jupyter Notebook entwickelt (Ablaufplan vgl. Abb. 5) und auf der Mediawiki Jupyter Plattform PAWS eingesetzt.
- Das verwendete Skript durchläuft auf Basis der Antwort der Mediawiki-API die Oberkategorie (Kategorie:Die_Gartenlaube_Artikel) zur Identifizierung der einzelnen Jahrgänge und holt im weiteren Schritt den Mediawiki-Text jedes einzelnen Artikels ab.
Mit RegularExpressions werden die einzelnen Parameter der Textbox auf der Seite extrahiert:
- Titel
- Subtitel
- (Erscheinungs-)Jahr
- Seite
- Heftnummer
- Autor
- Wikipedia-Link
- Die Werte im Feld Autor können hierbei reine Textstrings sein oder auch Wiki-Links zu den Autorenseiten in der Wikisource. In letzterem Fall ist es daher auch möglich eine Wikidata-ID für einen Autor zu gewinnen. Dafür muss über den vorhandenen Link der Wikisource-Autorenpage eine Mediawiki-API-Abfrage nach der QID gestartet werden.
- Der Wikipedia-Link stellt eine inhaltliche Klassifizierung des Artikels dar. Über die Mediawiki-Abfrage lässt sich die QID zur Verwendung als Schlagwort im Wikidata-Item auslesen.
- Abschließend werden die je Artikel vorhandenen Daten in einen Satz an QuickStatements9-Befehlen umgewandelt, um den Import der Daten zu ermöglichen.
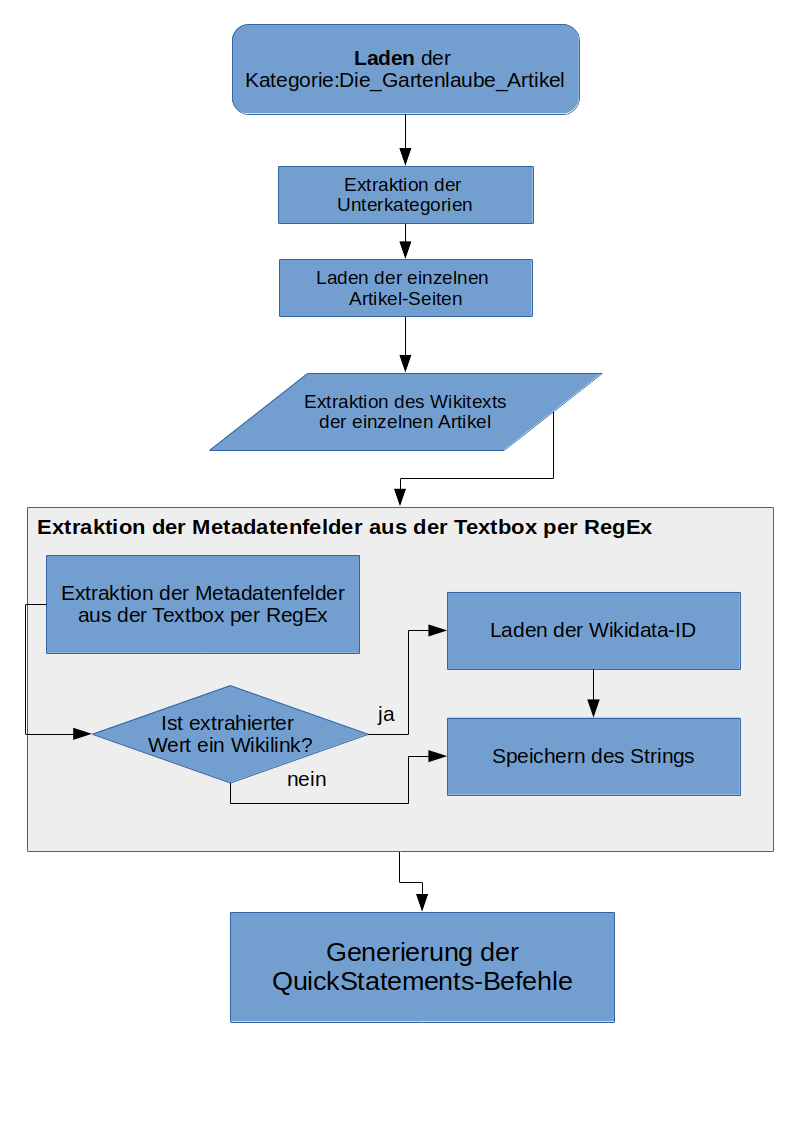
Abbildung 5: Ablaufplan des Python-Skripts zur Extraktion der Metadaten in der Wikisource-Vorlage und Konvertierung in QuickStatements-Befehle
Auswertung – Visualisierungen
Die nach Wikidata importierten bibliographischen Daten bilden einen strukturierten und verlinkten Nachweis der in Wikisource transkribierten Zeitschriftenartikel. Dies erlaubt beispielsweise die automatisierte Übernahme der bibliographischen Daten in lokale Bibliothekssysteme oder die Verwendung als Zitationsgrundlage in Literaturdatenbanken für wissenschaftliche Arbeiten.
Gleichzeitig ermöglicht dieser Datenbestand zahlreiche tabellarische Auswertungen und Visualisierungen10 in Form von Diagrammen oder Karten über die Summe aller Artikel der Zeitschrift:
- Scholia-Profil der Zeitschrift: https://tools.wmflabs.org/scholia/venue/Q655617
- Tabellarische Abfrage aller Artikel ohne Beschlagwortung und Listen für die Verbesserung der Datenqualität bezüglich bestimmter – unvollständiger – Merkmale (z.B. fehlende Illustratoren oder Untertitel von Illustrationen).
- Bubble-Chart für alle Schlagwörter der Artikel, Größe nach ihrer Häufigkeit der Verwendung.
- Karte mit allen Orten die in Artikeln beschrieben werden.
Ausblick
#DieDatenlaube versteht sich als ein fortlaufendes Begleitprojekt des Wikisource-Projektes für die Transkription und OCR-Korrektur von Die Gartenlaube der Jahrgänge 1853 bis 1899). Die systematische und strukturierte Beschreibung der Artikel der Zeitschrift in Wikidata war Ausgangspunkt und bleibt weiterhin eine Kernaufgabe, die laufend um neue „Baustellen‟ ergänzt wird wie beispielsweise:
- Fortführung der inhaltlichen Erschließung der Artikel11
- Identifizierung von fiktionalen Artikeln und generell die Zuordnung zu einer Literaturgattung. (zB Gedichte, Erzählungen aber auch Biographien, Reisebericht etc.)
- Verbesserung der Nachweise bei Artikeln die über mehrere Hefte hinweg erschienen sind (aber in Wikisource als [sinnvolle] Einheit dargestellt werden)
- Verlinkung der Zusammenhänge von Artikelserien (part of series, has part)
- Verlinkung und Verstärkung des Zusammenspiels mit Wikimedia-Commons (zB. Nachweis der biblioraphischen Fundstelle bei Illustrationen)
- Entwicklung neuer Fragestellungen für weitere Auswertungen mit Wikidata-Abfragen und Visualisierungen des Datenbestandes
- Entwicklung von Open Educational Ressources (OER) auf Basis der Texte und Daten der Illustrierten12
Wikimedia Deutschland e.V.: Wikisource-Broschüre, 2019, (Q66818271), sowie https://blog.wikimedia.de/2019/10/16/hilfe-fuer-die-datenlaube-mit-wikisourcewikidata-die-freie-quellensammlung-verbessern/↩︎.
Projektstand per 01.11.2019 https://de.wikisource.org/wiki/Die_Gartenlaube#Projektstand↩︎.
https://de.wikisource.org/w/index.php?title=Diskussion:Die_Gartenlaube&oldid=3573624#Vorschlag_f%C3%BCr_ein_Basisdatenmodell_der_Artikel_der_Gartenlaube ↩︎.
Fauconnier, Sandra: Structured Data on Commons and GLAM - Wikimania 2019.pdf - Wikimania, 2019. Online: https://commons.wikimedia.org/wiki/File:Structured_Data_on_Commons_and_GLAM_-_Wikimania_2019.pdf.↩︎.
SPARQL-Query der entsprechenden Datensätze: https://w.wiki/Bds ↩︎.
Das „älteste‟ Gartenlaube-Item ist somit Q15892076, welches am 05.03.2014 von einem Bot lediglich mit dem Sitelink (keine Labels oder Statements) angelegt wurde. Das jüngste (per 14.11.2019) Item ist Q75015200↩︎.
Alle Berechnungen und Auswertungen finden sich im Jupyter-Notebook Analyzing_WikidataItems.ipynb↩︎.
Anzumerken sei noch, dass diese numerische Auswertung letztlich auch dem Umstand geschuldet ist, dass zum damaligen Zeitpunkt die Analyse von Items mittels ShapeExpressions noch nicht in Wikidata derart umgesetzt war, wie es zum gegenwärtigen Zeitpunkt mit Verwendung von EntitySchema möglich ist.↩︎.
QuickStatements wurde als Tool verwendet, da OpenRefine zwar für die Bearbeitung der großen Masse an Daten gewisse Vorteile und eine tabellarische Übersichtlichkeit gebracht hätte, allerdings ist das Anlegen neuer Items mit Sitelinks in ein Wikiprojekt mit OpenRefine (noch) nicht möglich. ↩︎.
Unterschiedliche Auswertungen und Visualisierungen werden auf der Wikisource Diskussionsseite der Gartenlaube dokumentiert: https://de.wikisource.org/wiki/Wikisource:Wikidata#Die_Gartenlaube_(Abfragen).↩︎.
Bemme, Jens: Hilfe für die Datenlaube: mit [[Wikisource+Wikidata]] die freie Quellensammlung verbessern. (2019) https://blog.wikimedia.de/2019/10/16/hilfe-fuer-die-datenlaube-mit-wikisourcewikidata-die-freie-quellensammlung-verbessern/ ↩︎.
Vgl. HistoDigitaLE an der Universität Leipzig, https://de.wikisource.org/wiki/Wikisource:OER↩︎.
Veröffentlicht: 18.11.2019, (Q75682119)
